
Stable Diffusionで画像を生成していると、描きたい画像があるのにプロンプトになんと書けばいいか分からない。ということはありませんか?
またプロンプトの参考にするために、画像からプロンプトを逆生成したいこともあると思います。
そういった時に、画像から自動でプロンプトを教えてくれる方法について紹介したいと思います。
そこで今回は「似た棒人間から出力した場合の結果」から、2つを比較してみたいと思います。
結果
・画像から簡単に特徴を抽出できる
・画像から簡単に特徴を抽出できる
・寄与度のパーセント値が低いものをプロンプトに含めると、意図しない画像になる可能性がある
この記事を読むと
参考画像から、プロンプトを逆生成する方法の詳細が分かります。
※記事内に広告が含まれています。
「Tagger」とは?
「Tagger」とは、画像からプロンプトを自動で逆生成する機能のことです。
基本的には、服装や背景などで単語だけでは自身の思い描いた絵を描けない場合に使います。
例えば下記のような複雑な服装を描きたいとなった時に、どこまで表現すればいいか難しいですよね。

また、「Lora」で絵を学習する場合や「reference_only」の機能を使って同じキャラを描きたい場合に有効です。
「Tagger」のインストール
1.「Extensions」タブからInstall from URLを開きます。
2.URL for extension’s git repositoryに下記のアドレスを張り付けて、Installボタンをクリックしてます。
http://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git3.Installedで「Apply and restart UI」 ボタンをクリックして適用して再起動します。
4.念のためStable Diffusion web UI自体を再起動させて下さい。
「Tagger」というタブが追加されていれば、正常にインストールされた証拠です。
【検証】実際に画像から抽出してみた
実際に以前出力した画像を元にプロンプトを逆生成していきます。
プロンプトの出力結果
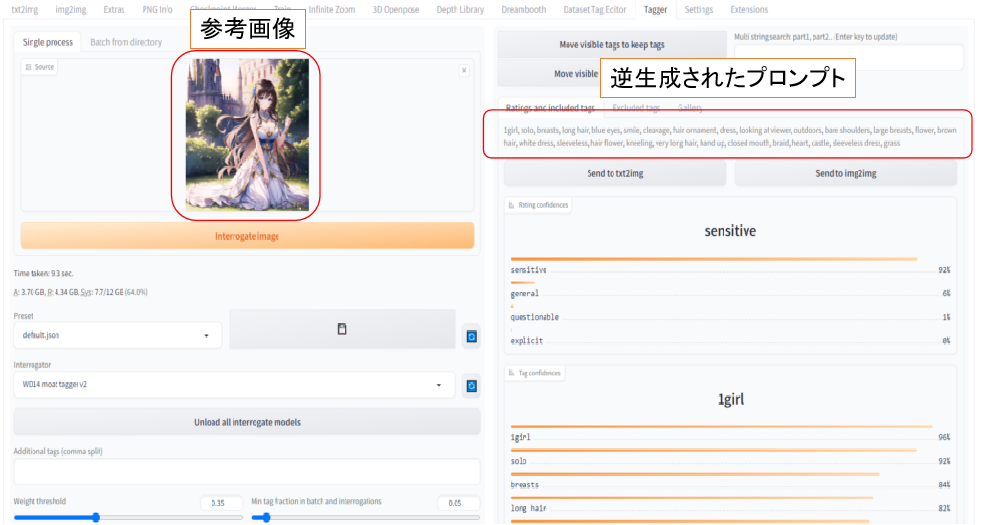
Taggerタブを開き、画面左にプロンプトを出力したい画像を入れ、「Interrogate image」ボタンをクリックします。
解析が完了すると、右側にプロンプトが逆生成され表示されます。
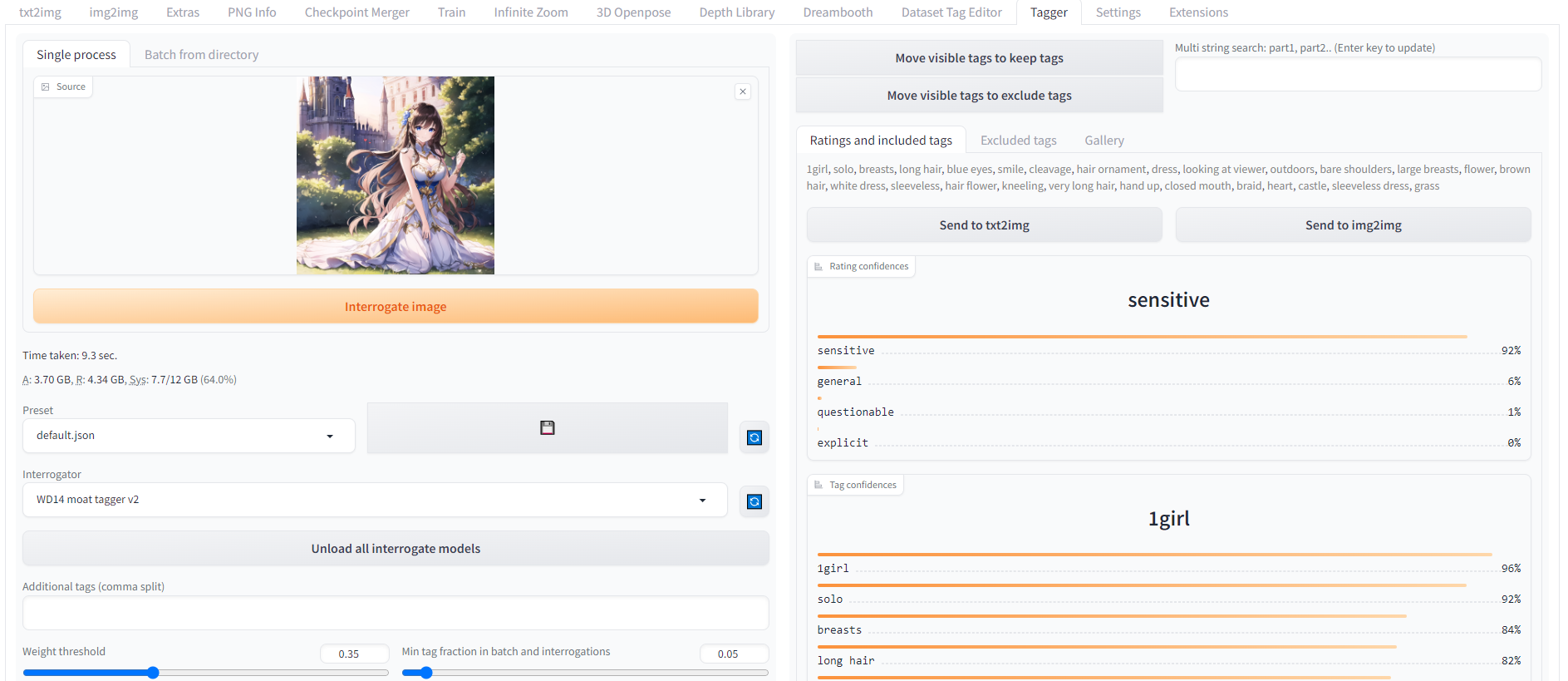
逆生成されたプロンプト
1girl, solo, breasts, long hair, blue eyes, smile, cleavage, hair ornament, dress, looking at viewer, outdoors, bare shoulders, large breasts, flower, brown hair, white dress, sleeveless, hair flower, kneeling, very long hair, hand up, closed mouth, braid, heart, castle, sleeveless dress, grass一人の少女という簡単な特徴から、こちらを見ている意味の「looking at viewer」なども出力されています。
逆生成されたプロンプトの下には、それぞれの単語との相関/関連値が表示されます。
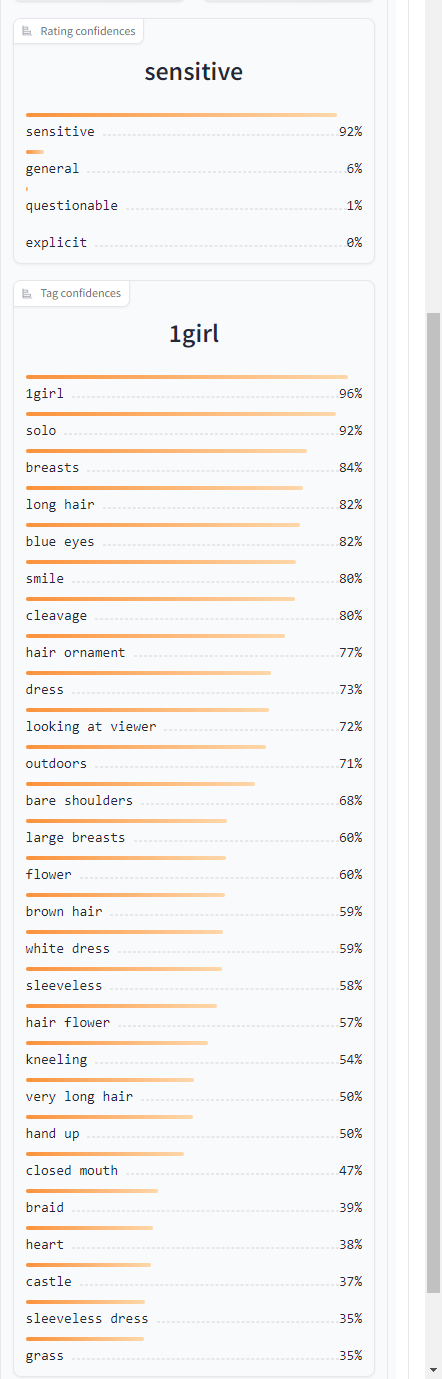
パーセント数が低いほど、「書かれているけど、そのプロンプトを使用して生成しても上手く反映されないかも」ぐらいに思ってください。
パーセント値が低いものプロンプトに組み込むことで逆に絵が破綻することもありますので注意が必要です。
また、Taggerでは逆生成されるプロンプトはポジティブのみになります。
そのため、品質や手足の欠損などに関するネガティブプロンプトは自分で打ち込む必要があります。
Taggerで出力したプロンプトから画像生成した結果
上記でも書いた通り、Taggerではポジティブプロンプトしか出力されないので、ネガティブプロンプトやSamplingmethodなどは自分で決めていきます。
上記のプロンプトに品質や手足欠損のネガティブプロンプトを追加して出力した結果が下記になります。
ドレスの感じや髪型などが元画像に近い結果が出力されました。


まとめ
今回は『Tagger』を使用して、絵からプロンプトを逆生成する方法について紹介しました。
改めて3行でまとめると…
・画像から簡単に特徴を抽出できる
・画像から簡単に特徴を抽出できる
・寄与度のパーセント値が低いものをプロンプトに含めると、意図しない画像になる可能性がある
スーツや制服など現実で名前が付いている服装は簡単に出力できますが、ファンタジーの世界など想像の世界の服装を説明するのは難しいですよね。
ですが、もし参考にしたい画像があれば、そこから特徴抽出することで、あなたの描きたい服装に近づけられるかもしれません。
是非Taggerを使って新しいプロンプトを逆生成して、自分の絵に活用してみてください!
StableDiffusionにお勧めのグラボ
ここまでの記事を読んでStableDiffusionを始めてみたいと思ったけど、どれを買ったか良いか分からない人向けに私の使っているグラボを紹介します。
私が使用しているグラボはNVIDIA GeForce RTX3060 搭載 グラフィックボード GDDR6 12GBになります。
StableDiffusionで絵を生成するときは、PCのCPUやメモリよりもグラボの性能が重要です。
StableDiffusionではVRAMが12GB以上であることが推奨されていますが、普通のゲーム用のグラボでは8GBのものが多いです。
経験上、一回のプロンプトで一発で望みの絵が出ることは少なく、10枚ぐらい出力してそこから近づけていく作業をします。
しかしVRAMが低いと1枚を生成する時間が長くなってしまいます(完全にVRAM依存ではないですが)
1枚の生成する時間が長いと、最終的なゴールまでの時間も多くかかってしまうので、推奨要領である12GBのグラボを買うことをお勧めします。
VRAMが低い=一度に計算できる数が少ない=生成速度が遅い
そのため解像度の高い絵を生成するのに時間がかかるだけでなく、生成できない可能性もあります(2GBや4GBなど)
Controlnet等、拡張機能を複数使用する場合やLora等の学習を行う場合は、より顕著にVRAMの差が出ます。
そのため単純にAIで出力してみたい。というだけでなく、その一歩先で色々やってみたい方は是非12GB以上を購入してみてください。
ちょっと試すだけなら、下記のような無料AI画像生成サービスを使うのも良いです。



コメント